Magento 2 robots.txt is a single text file at your store root that tells crawlers – Googlebot, Bingbot, GPTBot, ClaudeBot – which URLs they can crawl and which ones to skip. On Adobe Commerce that file is not a static asset on disk. It is stored in the database and rendered on demand at <domain>/robots.txt, edited through the admin panel rather than via SSH. The setup looks simple. The consequences of getting it wrong – index bloat from layered navigation, exposed checkout sessions, AI bots training on your product copy without your permission – are not.
This is Lesson 1 of scandiweb’s eight-part SEO Crash Course, rebuilt for the 2026 Adobe Commerce reality: AI crawlers, larger crawl budgets, and a SERP that now demands the actual admin path plus a copy-pasteable template, not a video wrapper. Robots.txt is one of the 14 checks in our technical SEO audit guide – start there if you have not audited the rest of the stack.
Overview
- Adobe Commerce stores robots.txt in the database and serves it on demand from
<domain>/robots.txt– you edit it under Content → Configuration → Design → Search Engine Robots. - A 2026-ready Magento robots.txt covers four jobs: hide sensitive paths (checkout, customer, admin), trim layered-navigation crawl waste, declare your sitemap, and govern AI crawler access (GPTBot, ClaudeBot, Google-Extended).
- Robots.txt controls crawling, not indexing – a Disallowed URL can still appear in Google if external sites link to it. Use a
noindexmeta tag when you need a page to stay out of results.
🚀 Quick takeaway: if your store still serves the default empty robots.txt that ships with Magento, you are leaking crawl budget on /checkout/cart/, layered-nav parameter combinations, and /customer/account/ – and you are giving every AI training bot a free pass on your catalog copy.
What is robots.txt and why it matters for Magento
Robots.txt is a plain-text file at the root of a host that follows the Robots Exclusion Protocol – a 1994 convention Google, Bing, and most large language model crawlers still respect. It lists rule groups, each tied to a User-agent, telling that agent which URL paths to crawl and which to skip.
For a Magento 2 store the stakes are higher than for a static brochure site. A catalog with 5,000 SKUs and four filter facets – color, size, price, brand – generates millions of URL combinations through layered navigation. Without a robots.txt that disallows the parameter URLs, Googlebot wastes its crawl budget on filter permutations instead of fresh product pages, and Anthropic’s ClaudeBot can hoover up duplicate listings for training without any return for you.
One point that trips up most Magento merchants: per Google’s robots.txt specification, robots.txt manages crawler traffic, not indexing. A page Disallowed in robots.txt can still appear in search results if Google finds it through external links – just without a snippet. To keep a page out of results entirely, use a noindex meta tag or an HTTP 401/403 response.
Where Magento stores robots.txt (and why it is not on disk)
SSH into your Adobe Commerce or Magento Open Source 2.4.x install and look for robots.txt in the document root. You will not find it. Per the official Adobe Commerce documentation, Magento stores robots.txt content in the database and generates it on demand. Requests to <domain>/robots.txt are routed through the application, the saved configuration is rendered into a text response, and the response is served. This applies to every 2.x line from 2.2 forward, including the current Adobe Commerce 2.4.8 release.
Practical implications:
- You edit robots.txt in the admin panel, not via FTP or SSH.
- Changes take effect after you flush the configuration cache.
- On multi-store installations each website can carry its own robots.txt, scoped per website in the configuration picker.
- On Adobe Commerce on Cloud you must enable robots.txt indexing in the Cloud Console (or via
magento-cloudCLI) before the file is served in Production. - On PWA Studio you may need to add
robots.txtto the UPWARD Front Name Allowlist under Stores → Configuration → General → Web if the request returns a 404.
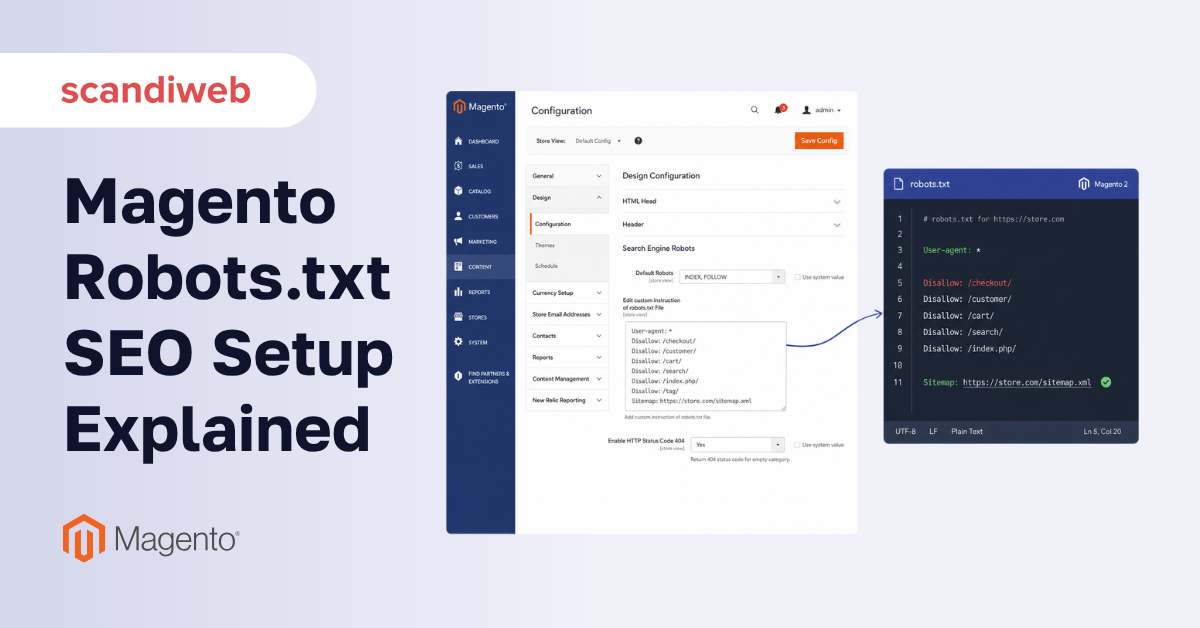
How to configure robots.txt in Magento 2 (admin path)
The canonical admin path on every supported Magento 2.x line is:
Content → Configuration → Design → Edit (your website or store view) → Search Engine Robots → “Edit custom instruction of robots.txt File”
Step-by-step:
- Log in to the Magento admin and go to Content → Configuration.
- In the Design Configuration grid, click Edit on the website or store row you want to configure.
- Expand the Search Engine Robots section.
- Set Default Robots to
INDEX, FOLLOW(this is the meta robots default for non-Disallowed pages, not a global noindex). - Paste your directives into Edit custom instruction of robots.txt File.
- Click Save Configuration, then flush the cache under System → Cache Management → Configuration.
- Open
<domain>/robots.txtin a private browser window and confirm the response matches what you pasted.
🚀 Quick takeaway: if your changes do not show up at /robots.txt, the configuration cache is almost always the cause. Flush it. If the file 404s entirely on Adobe Commerce on Cloud, enable robots.txt serving in the Cloud Console.
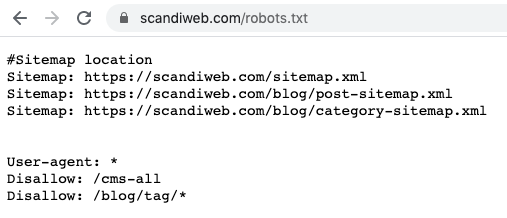
Recommended Magento 2 robots.txt template (2026)
The template below covers the directories every Magento 2 store should hide from search crawlers plus the layered-navigation parameter list that controls index bloat. Drop it into the admin textarea, save, flush cache, verify at <domain>/robots.txt, then customize for any non-default URL paths your store uses.
# Magento 2 robots.txt – 2026 baseline
User-agent: *
# Sensitive customer & checkout paths
Disallow: /checkout/
Disallow: /customer/
Disallow: /cart/
Disallow: /onestepcheckout/
Disallow: /sales/
Disallow: /wishlist/
Disallow: /sendfriend/
Disallow: /review/
Disallow: /catalog/product_compare/
Disallow: /catalogsearch/
Disallow: /downloadable/
# Application & system paths
Disallow: /app/
Disallow: /bin/
Disallow: /dev/
Disallow: /lib/
Disallow: /phpserver/
Disallow: /pkginfo/
Disallow: /report/
Disallow: /setup/
Disallow: /update/
Disallow: /var/
Disallow: /vendor/
Disallow: /index.php/
Disallow: /admin/
# Allow critical assets so Google can render product pages
Allow: /media/
Allow: /static/
Allow: /pub/media/
Allow: /pub/static/
# Layered navigation & session parameters
Disallow: /*?SID=
Disallow: /*?___store=
Disallow: /*?___from_store=
Disallow: /*?p=
Disallow: /*?limit=
Disallow: /*?mode=
Disallow: /*?dir=
Disallow: /*?order=
Disallow: /*?price=
Disallow: /*?color=
Disallow: /*?size=
Disallow: /*?material=
Disallow: /*?cat=
# Sitemap
Sitemap: https://example.com/sitemap.xmlTwo things to flag before you paste this verbatim:
- The
Allow: /media/andAllow: /static/lines are non-negotiable. Magento renders product images, CSS, and JavaScript from these paths. Disallow them, or paste a blanketDisallow: /at the top, and Google cannot render your pages – Core Web Vitals and rankings collapse together. Per Google’s Robots Exclusion Protocol spec, the most specific Allow/Disallow rule wins, which makes the Allow lines safe alongside the Disallows. - Replace
example.comwith your production domain in theSitemap:line. See how to configure the Magento 2 XML sitemap for the matching admin path and cron settings.
Blocking AI crawlers in your Magento robots.txt
The single biggest 2026 update to Magento robots.txt practice is AI crawler governance. Three vendor decisions matter, and each ships its own User-agent string.
OpenAI. OpenAI documents three User-agents: GPTBot for training, ChatGPT-User for in-product retrieval triggered when a user pastes your URL into ChatGPT, and OAI-SearchBot for the ChatGPT search index. The 2026 stance for commerce stores is to block training (GPTBot) and allow retrieval (ChatGPT-User, OAI-SearchBot) so your brand surfaces in ChatGPT answers without feeding free training material.
Anthropic. Anthropic publishes the same three-way split: ClaudeBot for training, Claude-User for in-product retrieval, and Claude-SearchBot for Claude’s web search. Mirror your OpenAI policy here unless you have a reason to diverge.
Google. Google-Extended controls whether your content can train Gemini and Vertex AI. Per Google’s crawler documentation, blocking Google-Extended does not affect Googlebot crawling or your search rankings – it only opts you out of Gemini training. This is the safest AI block to add to any Magento store.
Append the block below to the template above:
# AI crawlers – block training, allow retrieval
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Retrieval bots – allow so your brand surfaces in AI answers
User-agent: ChatGPT-User
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Amazonbot
Allow: /🚀 Quick takeaway: the most common 2026 mistake is blocking ChatGPT-User and OAI-SearchBot alongside GPTBot. Block training, keep retrieval. If a customer asks ChatGPT “what jackets does [your brand] sell,” you want your store to be in the answer.
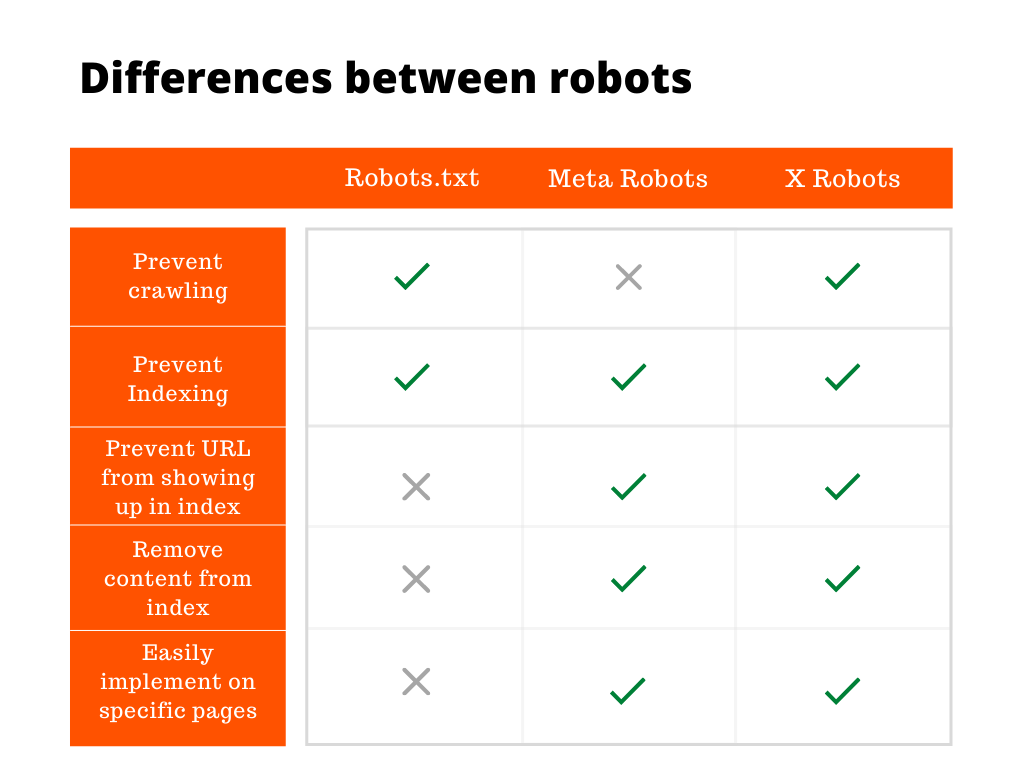
Robots.txt vs noindex: which one should you use?
This is the question that ends every Magento SEO audit conversation, and the answer is not “use both.” Robots.txt and noindex solve different problems.
| Need | Use robots.txt Disallow | Use noindex meta tag |
|---|---|---|
| Stop crawler from hitting a path to save crawl budget | ✅ | ❌ (page still gets crawled) |
| Keep a URL out of Google’s index entirely | ❌ (URL can still be indexed via external links) | ✅ |
| Hide thank-you pages, internal search, account pages | ✅ for crawl budget | ✅ for indexing |
| Block AI training | ✅ | ❌ (most LLM crawlers ignore meta tags) |
| Suppress an internal staging URL | ❌ (use HTTP auth or noindex) | ✅ |
The trap: if you Disallow a URL in robots.txt and add a noindex meta tag, Google cannot read the meta tag because it is not allowed to crawl the page – and the URL may stay indexed indefinitely. Pick one mechanism per URL. As a rule of thumb, robots.txt is the crawl-budget tool, noindex is the indexing tool, and HTTP authentication is the privacy tool.
Once your robots.txt directs crawlers to the right pages, the next layer of crawl control is canonical tags – covered in lesson 2 of this series.
Crawl budget on Magento: layered navigation and filter parameters
Layered navigation is the single biggest crawl-budget drain on Magento stores. A category with four filter facets – color, size, price, brand – and ten values each generates 10,000 parameter URL combinations. On a store with 200 categories that is 2 million low-value URLs competing for crawl attention.
The parameter Disallow block in the template above (Disallow: /*?color=, /*?size=, etc) is the brute-force fix. Pair it with three controls:
- Canonical tags on category pages pointing to the unfiltered URL – the indexing layer that catches what robots.txt misses.
- Google Search Console URL Parameters report to surface which parameters Googlebot is wasting time on.
- Sitemap exclusion – your XML sitemap should include only canonical category and product pages, never filter URLs.
Pair robots.txt with proper canonical hygiene – our 2026 duplicate content guide covers the Magento layered-navigation patterns most likely to bloat your index.
🚀 Quick takeaway: if your Search Console “Discovered – currently not indexed” bucket is dominated by parameter URLs, your robots.txt is the first fix. Index bloat hurts the rest of your catalog by diluting crawl attention.
How to test your Magento robots.txt
Three tools, in this order.
1. Direct fetch. Open <domain>/robots.txt in a private browser window or curl it. Confirm HTTP 200, content matching what you saved, and a file under 500 KB (Google’s hard limit). If it 404s, check Cache Management and – on Adobe Commerce on Cloud – the robots.txt serving toggle in the Cloud Console.
2. Google Search Console URL Inspection. Paste any URL into the inspection bar and click Test Live URL. Google’s URL Inspection tool surfaces the exact robots.txt rule blocking a given URL. Inspect a product URL (Allowed), a checkout URL (Blocked), and a parameter URL (Blocked).
3. Third-party validator. Tools like robotstxt.org and TechnicalSEO.com’s tester let you paste your file plus a test URL and see which rule matches. After deploying, validate inside Google Search Console – covered in Lesson 8 of this series.
Common Magento robots.txt mistakes to avoid
Five mistakes account for almost every robots.txt failure scandiweb has seen across Magento migrations:
- Blocking
/static/or/media/. Google needs CSS, JavaScript, and product images to render pages. Disallow these and your Core Web Vitals scores tank along with your rankings. The Allow lines in the template above protect you, but only if you do not paste a blanketDisallow: /ahead of them. - Forgetting to flush the configuration cache after saving the admin form. The file does not update at
<domain>/robots.txtuntil the cache is cleared. - Using robots.txt to hide pages from search results. Robots.txt controls crawl, not indexing. A Disallowed URL with inbound links from external sites can still appear in Google with no snippet. Use
noindexfor indexing control. - Leaving the default empty robots.txt in Production. Magento ships with an effectively empty file. Doing nothing means every layered-nav URL is fair game for Googlebot.
- Forgetting the Sitemap directive, or pointing it at a sitemap path your store does not generate. Always cross-check the path against your live
<domain>/sitemap.xml. If you are migrating a Magento store, the robots.txt audit pairs with 301 redirect mapping – Lesson 7 of this series – because your old store’s Disallowed paths often need fresh redirects on the new domain.
🚀 Quick takeaway: the most expensive of these mistakes is the first one. scandiweb has audited Magento stores where Disallow: /static/ was hiding the entire theme bundle from Googlebot – and the merchant could not understand why their rankings had collapsed three weeks after a “minor SEO tweak.”
X-Robots-Tag for PWA and headless Magento storefronts
On Magento PWA Studio, ScandiPWA, or Hyvä-headless frontends, JavaScript-rendered pages can be slow to expose meta robots tags to crawlers. X-Robots-Tag in the HTTP response header is the more reliable signal. Configure it at the Nginx, Apache, or Fastly edge layer:
location ~* ^/customer/ {
add_header X-Robots-Tag "noindex, nofollow" always;
}Use robots.txt Disallow for paths that should not be crawled at all, and X-Robots-Tag for paths that should be crawled for canonical or link signals but kept out of the index.
How often should I update my Magento robots.txt?
Treat robots.txt as a versioned configuration artifact. Review it quarterly alongside your other technical SEO checks, before every site launch or replatform, and after any layered-navigation change. Each update should pass three checks: the file is under 500 KB, the Allow lines protect /media/ and /static/, and the Sitemap directive points to a sitemap the store actually generates.
FAQ
Where is the Magento 2 robots.txt file located?
Adobe Commerce and Magento Open Source store robots.txt in the database, not on the filesystem. The file is generated on demand at <domain>/robots.txt. You edit it through the admin under Content → Configuration → Design → Search Engine Robots.
How do I edit robots.txt in Magento 2?
Log in to the admin, go to Content → Configuration, click Edit on your website’s design configuration row, expand the Search Engine Robots section, paste your directives into “Edit custom instruction of robots.txt File,” save, and flush the configuration cache.
Should I block /checkout/ in Magento robots.txt?
Yes. The checkout flow contains session-specific URLs and dynamic cart states that have no search value and waste crawl budget. Disallow /checkout/, /cart/, and /customer/ at minimum.
Does Magento robots.txt block AI crawlers like ChatGPT and Claude?
Only if you add explicit rules. The default Magento robots.txt does not mention AI crawlers. Add User-agent blocks for GPTBot, ClaudeBot, and Google-Extended to block training, and allow ChatGPT-User and Claude-User if you want retrieval traffic.
Is robots.txt enough to keep pages out of Google’s index?
No. Robots.txt controls crawling, not indexing. A page Disallowed in robots.txt can still appear in search results if external sites link to it. Use a noindex meta tag or HTTP authentication for true indexing control.
Why are my robots.txt changes not showing up at /robots.txt?
The configuration cache is almost always the cause. Flush it under System → Cache Management → Configuration. On Adobe Commerce on Cloud, also check that robots.txt serving is enabled in the Cloud Console for the Production environment.
Can I have a different robots.txt for each website on a multi-store Magento install?
Yes. Each website in a multi-store setup has its own design configuration. Set the scope in the admin’s configuration scope picker before editing the Search Engine Robots section.
What is the maximum size of a Magento robots.txt file?
Google enforces a 500 KB hard limit on robots.txt files. Magento has no smaller limit in the admin, but you should never approach 500 KB – a robots.txt over a few kilobytes usually signals over-blocking or a pattern problem.
Watch the four-minute version
Continue the SEO Crash Course
This is Lesson 1. The full eight-part series:
- Lesson 2 – Canonical Tags
- Lesson 3 – International SEO and Hreflang
- Lesson 4 – XML Sitemap
- Lesson 5 – Structured Data Markup
- Lesson 6 – Client-Side Rendering and Dynamic Rendering
- Lesson 7 – 301 Redirect Mapping
- Lesson 8 – Google Search Console and Indexing
- Series hub – SEO Crash Course
Robots.txt is one knob on a large Magento SEO panel – index hygiene, Core Web Vitals, structured data, and crawl budget all interact. If your store is leaking crawl budget or stuck on page 3 for keywords you should own, let scandiweb audit your Magento SEO end to end.

Share on: