
When developing software applications, most development consists of 2 parts: frontend development and backend development. Connecting these general areas is another important concept known as APIs.
What is an API?
An API (Application Programming Interface) is a set of rules defining how applications or devices can connect and communicate. In other words, APIs are the messengers between requests and responses. APIs exchange commands and data, and that requires clear protocols and architectures.
What API architectures exist?
There are three categories of API protocols or architectures:
- REST
- RPC
- SOAP
Web developers have been using REST to build APIs for a long time.
REST stands for Representational State Transfer—guidelines developers follow when creating their API. One of them states that a client has to be able to get a piece of data (resource) when you link to a specific URL (endpoint).

What problems does REST have?
REST API is centered around individual endpoints, so to collect all needed data, a developer has to combine multiple endpoints. REST API approach problems are:
- A lot of endpoints to discover, learn, and document for different resources
- Over-fetching (meaning there is data in the response you don’t use) and under-fetching (not having enough data with a call to an endpoint, forcing you to call a second endpoint) of information.
To solve these problems, GraphQL was introduced, which is the preferable way of building APIs nowadays.
What is GraphQL?
GraphQL is a query language and server-side runtime for APIs that prioritizes giving clients precisely the data they request and no more, unlike other API-building methods. For example, REST depends on endpoints, thus unable to fetch only the needed data.
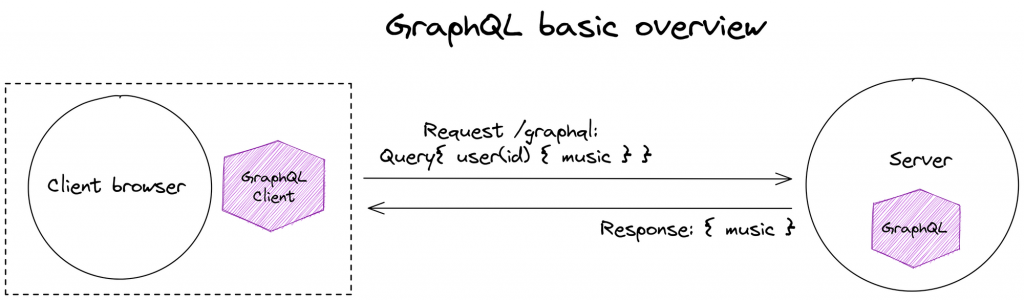
Why use GraphQL instead of REST?
GraphQL came to solve the problems REST had.
- It gives us a single endpoint; no more creating new versions for the same API
- GraphQL is strongly typed; you can validate a query within the GraphQL type system before execution. It helps us build powerful APIs, and the client is more aware of what data they can get and what operations they can perform.
How does GraphQL work?
Every GraphQL service defines a set of types that describe the possible data you can query on that service (that’s the schema). Then, when queries and mutations come in, they are validated and executed against that schema and processed using resolvers.
So a complete GraphQL implementation must have two parts: schemas & resolvers.
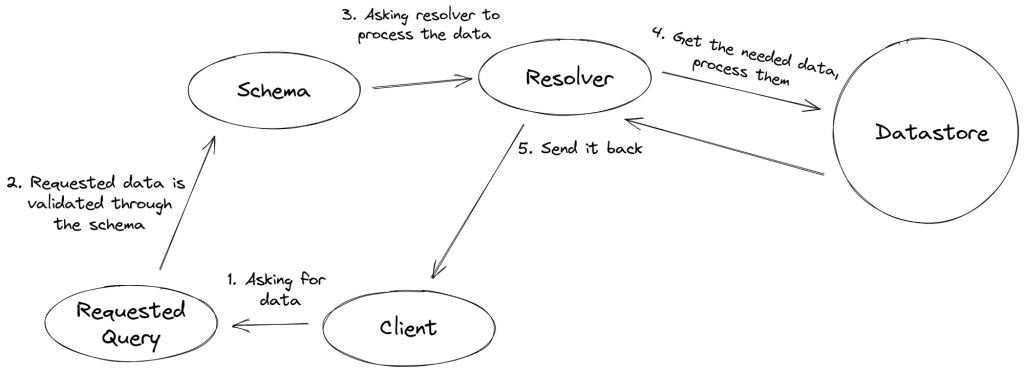
What are queries and mutations?
A GraphQL operation can either be
- Read operation, known as Query, is used to read or fetch values
- Write operation, known as Mutation, is used to write or delete values.
In both cases, the operation is a simple string that a GraphQL server can parse and respond to with specifically formatted data. JSON is usually the popular response format for mobile and web applications.
What is a schema?
A schema is a collection of GraphQL types. GraphQL uses it to describe the shape of your available data. Schema is one of the key concepts when working with GraphQL API. It defines how the client can request the data and specifies the capabilities of the API. It’s like a contract between the server and the client.
What are resolvers?
Resolver is a function that generates responses for GraphQL queries & mutations by acting as a GraphQL query handler. It’s defined within the GraphQL schema that a particular query will use the resolver, so it is responsible for fetching data, processing data, then transforming the fetched and processed data into a GraphQL array format. Then, the resolver returns the results wrapped by a callable function.
What is the role of the developer?
- Create a schema for allowed document fields and field types
- Create and implement a resolver to return corresponding data.
Was this article helpful? There’s more where this came from! Browse our tech category in the blog, or contact our team directly!

Share on: