
Planning a big promotion that you hope will double or even triple your store’s traffic in no time? Consider auto scaling or risk experiencing downtime on the most important part of your campaign—the promo launch!
In this article, we’ll help you understand how auto scaling works in Magento 2, and why it’s your best option whether you’re running occasional or frequent promotions on your eCommerce store.
You create sales promotions because you want to increase sales. And that starts with getting more people to your site to browse your products. But what if your site freezes as soon as the promo starts because your server’s resources can’t handle the sudden increase in traffic?
No, you don’t need to pay hefty upgrade fees just to see you through a single promotion, or even one promo every month. Auto scaling will save you such unnecessary costs and keep your store running as smoothly as any other day.
What is auto scaling?
Auto scaling is a feature of cloud computing that allows for computational resources to be dynamically adjusted as the demand for them increases or decreases.
Auto scaling in Magento 2 via ReadyMage
ReadyMage is a development platform that lets you launch projects with Magento in the backend and ScandiPWA in the frontend in under 15 minutes. ReadyMage is deployed on Kubernetes clusters, which provide auto scaling to manage fluctuations in traffic and resource demand for your eCommerce store.
In ReadyMage, your infrastructure components—MySQL, frontend, backend, Varnish, Elasticsearch—run inside containers, which are grouped into pods. Pods are the smallest deployable units in Kubernetes, and they run on nodes (virtual AWS servers).
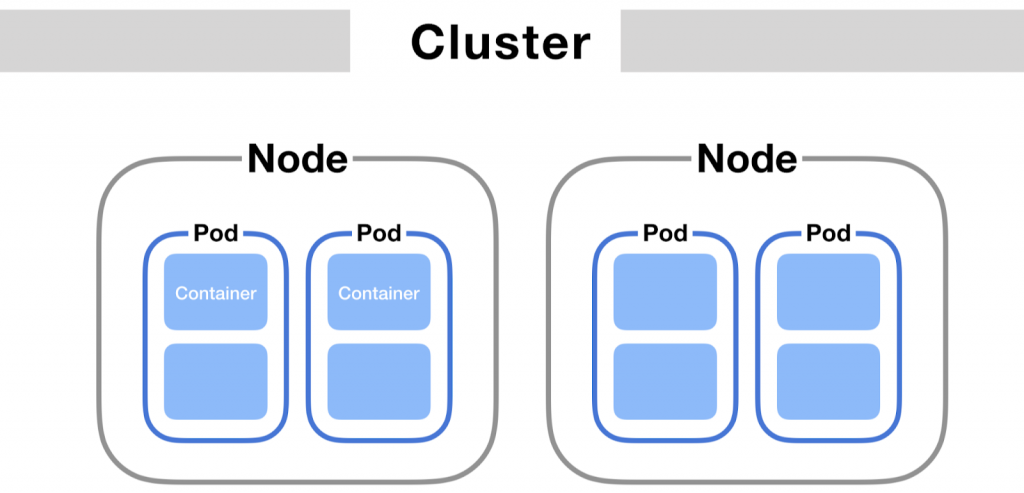

Why is auto scaling needed?
Imagine you have a production instance with the server resources set to handle only normal traffic. Once the sales promo period starts and the traffic increases, ideally, we want the website to still manage and not have downtime. But at the same time, we want to keep default resources low so you don’t need to pay for the resources that are not used. This is where auto scaling proves very useful.
Given the ReadyMage infrastructure, we are able to avoid keeping resource limits of one pod higher than what is normally needed while making it possible to automatically assign more server resources as the demand increases.
Real-life case study
An international beauty products store hosted on ReadyMage experienced a surge in traffic upon launching a highly promoted sales event.
On 21 June 2021, Beauty Works received traffic that was 3 times as much as what they would normally get.
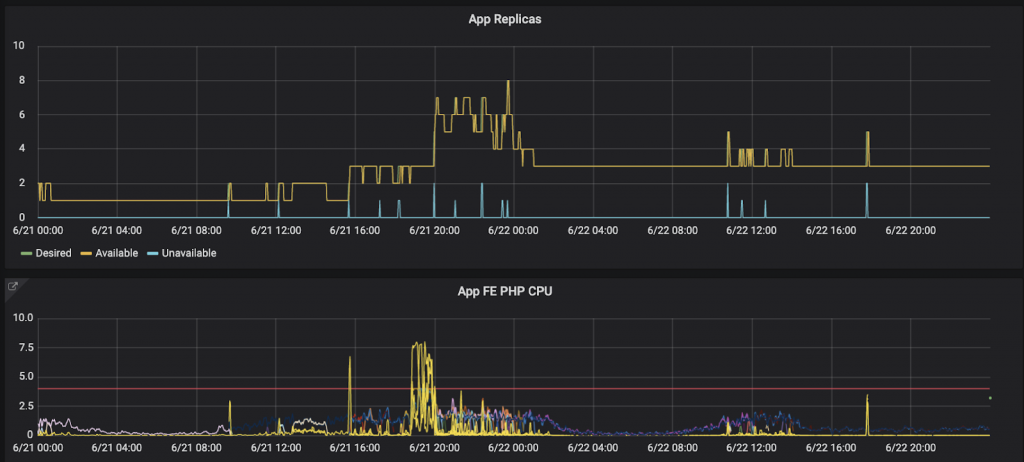
At 8:00 p.m., when the traffic began going up, the infrastructure behind ReadyMage started creating pods one by one until the total CPU amount could handle all the incoming traffic.
Once the traffic normalized after 1:00 a.m, the unused pods were scaled down.
How does it work?
ReadyMage makes auto scaling possible for front-end and back-end pods.
Horizontal scaling allows for the automatic increase or decrease in the number of running pods as your application’s usage changes. This graph below shows the CPU usage for another website.
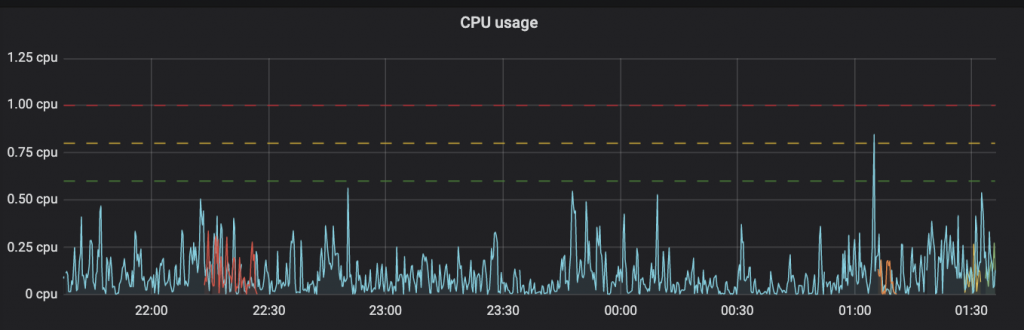

As your consumed resources hit the HPA (Horizontal Pod Auto scaling) limit, the green line on the graph above, ReadyMage facilitates the creation of new pod replicas for the same infrastructure component and distributes the traffic equally between all pods.
The HPA limit is calculated programmatically based on the requested resource amount that is set for the pod, the yellow line on the graph above. In ReadyMage, the HPA is 75% of this amount. It is less than the pod limit for safety purposes—thus, if setting up the pod replica takes longer than what is ideal, your current pod will still have some available resources while waiting for the replica to be ready.
Still looking at the same graph above, you’ll see that the total limit is at 0.80 CPU and the HPA is 0.60 CPU. At 1:05 a.m., the resources used hit the HPA limit so a new replica of the same pod was created.
As for scaling down, traffic is checked every 5 minutes for front-end and back-end pods. If the total consumed CPU can be handled by fewer pods, resource allocation is scaled down by killing unused pods.
The graph below shows that an additional pod was created at 1:05 a.m. but then killed at 1:10 a.m. as the system detected that additional resources were no longer needed.
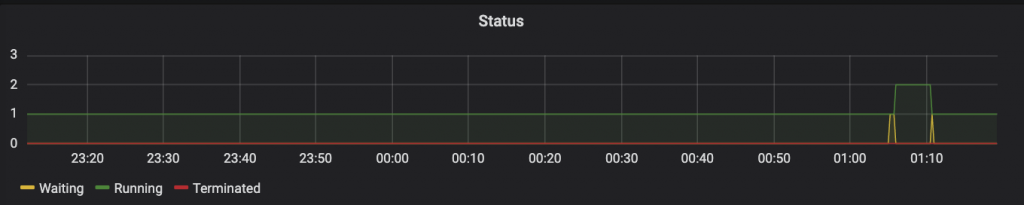
Hence, when site traffic is back to normal, resource allocation returns to the default level. So there is no need to pay for more resources than are necessary.
Still have questions and want to know more about how auto scaling works? Send us a message and we’ll be happy to tell you more.
If you’re interested in migrating your existing store to Magento 2 or curious about ReadyMage and ScandiPWA, let us know and our certified Magento team is always ready to support you.

Share on: