Tag Content Categories
Every tag in HTML is a member of a content category. There are three main types of content categories: main, form-related, and content-specific.
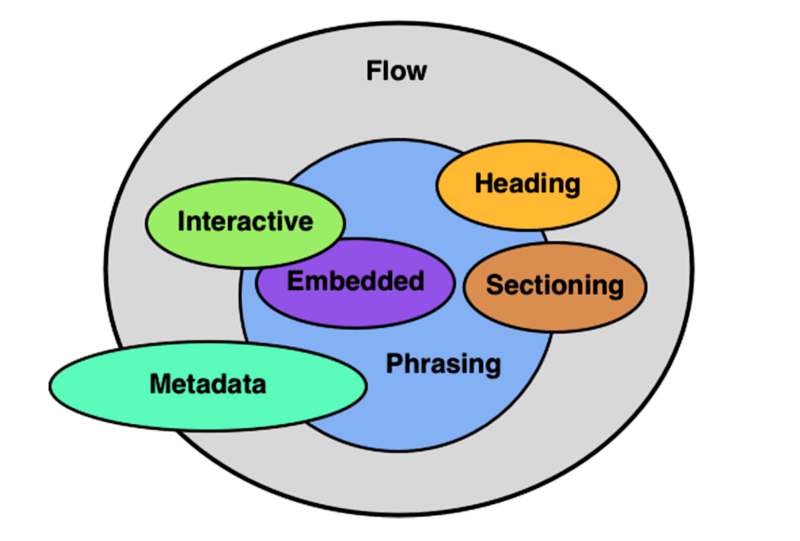
When developers discuss the main content category type, they are usually referring to three subtypes: Flow Content, Sectioning Content, Phrasing Content.
Flow content — usually contains text or embedded content.
Sectioning content — usually creates sections in the current outline.
Phrasing content — defines the text and the mark-up it contains.
How can parsed HTML be different from the source?
Sometimes, elements have special tag omission rules. These are usually applied if the immediately following children of an element do not follow a specific rule.
According to the specification, the
tag allows only Phrasing content to be entered into it:
The start tag is required. The end tag may be omitted if the
element is immediately followed by [list of elements which accept Flow content]
It’s important to clarify that in this case, immediately followed not only applies to first child, but any first-level child. So any inside of will be omitted. For example:
<p><div></div></p>Will be compiled into:
<p></p><div></div></p></p>Why is parsing quirky?
Let’s take a look at the following example: the end tag may be omitted if the element is not immediately followed by a comment, and if it contains a element that is either not empty or whose start tag is present.
<html><body></body><!-— document end --></html>Will be parsed into:
<html><body></body><!-— document end --></html>Notice there’s no difference. However:
<html>
<body></body>
<!-— document end --></html>Will be parsed into:
<html>
<body><!-— document end --></body>
</html>In both cases, the immediate child of the end tag is the comment, the is empty and the start tag is present. So why are the results different? There are no tabs / spaces, which could be treated by the browser like a text node (new lines are not treated at all). So it’s not clear why does these two examples work different.
How do semantic elements complicate tag omission?
With the introduction of new elements, like < address >, < time > etc, it became more and more difficult to know the element specification. For example, < time > accepts Phrasing content, while < address > accepts Flow content. Why is this the case? < address > logically indicates an address, and time — a time. Why are their specifications so different?
Returning to the < p > example, remember that < p > does not accept any element which accepts Flow content. Imagine you want to write a paragraph given the date, time and the address of an event:
<p>The event will be held on <time datetime="02–12–2018">second of December</time> in <address>Raddison Hotel Latvia</address>.</p>Seems logical, but it won’t work. Here is what will be parsed:
<p>The event will be held on <time datetime="02–12–2018">second of December</time> in</p>
<address>Raddison Hotel Latvia</address>
<p>.</p>Because, as marked above, the element does not accept elements which accept Flow content in itself. This is why introducing semantic elements may cause issues. It is always important to check specification for every semantic element, before working with it.


Share on: