
Salesforce Data Cloud is a Customer Data Platform (CDP) designed to bring together fragmented customer interactions across various touchpoints. Its primary mission is to create a comprehensive, unified view of each customer, enabling businesses to deliver more personalized and effective experiences.
At the core of this unification is identity resolution—Data Cloud’s capability to accurately identify individual customers across different systems. This function distinguishes unique persons despite varying identifiers, incomplete data, or minor discrepancies between records.
In this article, we’ll briefly cover key concepts of identity resolution within Salesforce Data Cloud, then dive straight into practical advice and real-world implementation insights. This guide will be particularly useful for anyone preparing to implement Data Cloud, managing identity resolution projects, or navigating common challenges—tips and insights we wish we’d had when starting out.
Also read:
The Complete Guide to Data Ingestion in Salesforce Data Cloud
How identity resolution handles customer data inconsistencies
Imagine a customer like Emily Swift who interacts with a business through multiple channels. In one instance, she uses the email [email protected] when purchasing at a physical store with her loyalty card. Later, she shops online using a different email, [email protected].
What makes Identity Resolution truly powerful is its ability to handle real-world data inconsistencies. For example, in the online store’s system, her name might be accidentally entered as “Emly Swift” (a simple typo). Or perhaps her address is recorded with slight variations: “123 Main Street, Apt 4B” versus “123 Main Street, Apartment 4B”. Fuzzy matching capabilities in Data Cloud can intelligently recognize these as variations of the same customer’s information.
This also helps with customers who have tricky surnames that cashiers often misspell.
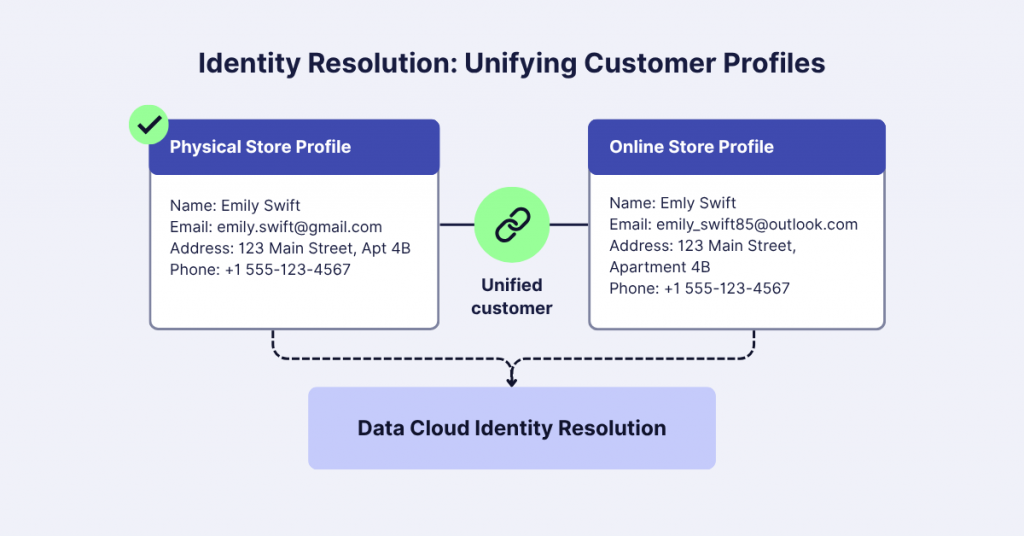
While the emails and names might differ slightly, other details remain consistent: her core personal information, purchase history, and contact details. Identity Resolution in Data Cloud tackles this complexity. It uses smart matching rules based on Data Model Object (DMO) values to recognize that these seemingly different profiles belong to the same customer.
Identity Resolution in Data Cloud operates through rulesets—collections of matching rules that determine when records from different sources represent the same customer. These rules examine specific attributes to identify matches despite variations or inconsistencies.
When the system identifies matching profiles based on these rules, it creates a unified profile combining all customer data. Reconciliation rules then determine which value to keep when multiple sources have different data for the same attribute (for example, selecting which email address becomes primary in the unified record).
Why identity resolution matters for your business
Identity resolution offers substantial business value beyond its technical aspects. From a reporting and decision-making perspective, it directly impacts how organizations understand their customer base.
One of the most significant impacts is on customer count accuracy. Without proper identity resolution, businesses often face customer overcounting due to duplicates across systems. A single customer might appear as multiple individuals when their web session, email interactions, and in-store purchases are treated as separate entities.
This incorrect customer count affects other key business metrics, including:
- Average Revenue Per User (ARPU)
- Customer Acquisition Cost (CAC)
- Return on Marketing Investment (ROMI)
- Conversion rates across touchpoints.
This capability is crucial because without a unified customer view, businesses struggle to accurately:
- Calculate customer lifetime value (LTV)
- Measure customer retention
- Understand purchase history
- Personalize marketing and service offerings.
When decision-makers rely on data with artificially inflated customer counts, they might underestimate the true value of each relationship or misallocate resources. Identity resolution transforms fragmented data into reliable business intelligence, enabling more accurate forecasting and strategic planning.
Now that we’ve covered the basics, let’s move on to practical steps.
Preparing your data for identity resolution
Data Preparation is crucial when working with Identity Resolution. When you’re setting up Salesforce Data Cloud, you’ll be connecting data from different systems that capture and store information in their own unique ways.
Important: Successful Identity Resolution requires understanding all the ways customers interact with your business and thinking through potential challenges in matching their information.
Data from different sources rarely comes ready to use. You’ll often need to clean and reshape the information before you can start matching records. This means working with data from your CRM, online store, point-of-sale systems, and other tools to make sure everything lines up correctly.
Making data consistent with standardization and harmonization
Data standardization and harmonization might sound similar, but they’re not quite the same. Standardization focuses on converting data to a consistent format, while harmonization goes deeper, ensuring data from different sources can work together seamlessly.
Data harmonization is a big part of any Data Cloud setup. When you’re connecting data from multiple sources, you’ll quickly discover that the same information can look wildly different across systems.
Take country names as a perfect example. Your web orders might use “US”, while an offline tool prints “The United States”. Dive into customer-entered data, and you’ll find even more variations: ‘The US’, ‘USA’, ‘United States of America’, ‘The United States’, ‘usa’. To a human, these all mean the same thing. To a computer matching system, they’re completely different.
Important: Converting data points to a consistent format is crucial for accurate identity resolution and creating meaningful customer insights.
When it comes to data transformation, you have two main approaches:
- External data transformation. Cloud platforms like AWS Glue or Azure Data Factory offer powerful data pipeline tools. These are excellent for complex transformations, especially with large, complicated datasets. They provide more flexibility and advanced processing capabilities.
- Data cloud transforms. Salesforce Data Cloud also has built-in transformation capabilities. These work great for simpler data transformation tasks, keeping everything within the same ecosystem and saving you time.
Phone numbers present another interesting standardization challenge. Data Cloud recommends using the E.164 format, which isn’t the default for many systems. This means you’ll likely need to create a transformation that generates a new column with correctly formatted phone numbers.
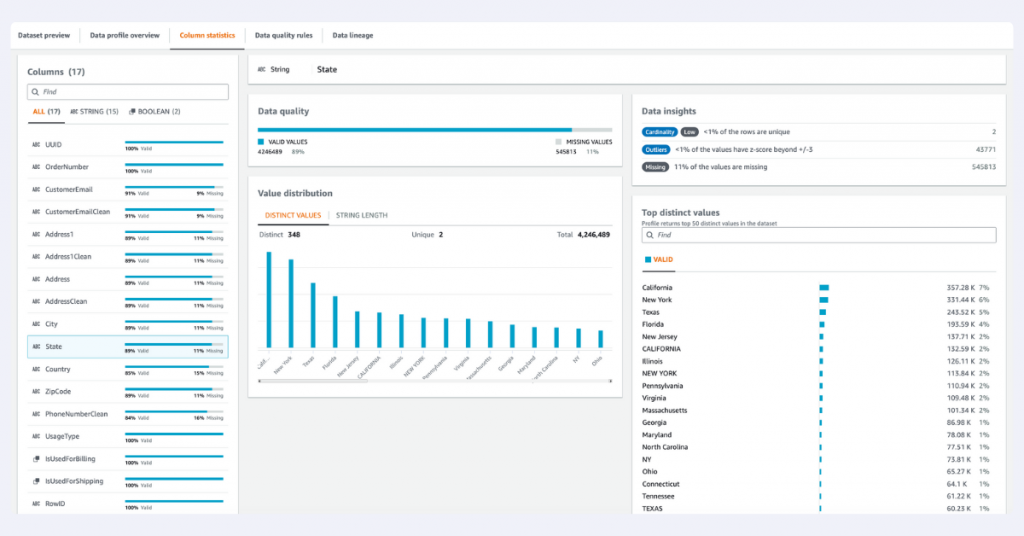
Pro tip: Perform data profiling on your historical data before setting up transformations. This helps you understand common patterns, spot outliers, and create more effective standardization rules.
For data profiling, you have several options:
- Use specialized libraries like Python’s Data Profiler
- Leverage cloud computing platforms
- Run analysis with SQL or Excel for simpler datasets
The ultimate goal is to create a unified, reliable view of your customer data that works across all your systems.
Keeping your data clean with strategic blacklisting
Not all customer data is created equal. Sometimes, you need to be strategic about what information gets processed in your Identity Resolution setup.
Consider a multichannel retail business with a complex backend ecosystem. In one of their unique scenarios, they sell certain clothing lines through specialized drop-shipping partners. These third-party shipping arrangements create interesting data complexities in the backend systems. When these orders are processed, the shipping and customer data appear differently compared to direct sales channels. The billing might reflect the end customer, while shipping details consistently show the drop-shipper’s information.
In this case, you probably don’t want to run those shipping customer details through your Identity Resolution process.
Pro tip: There’s a crucial distinction in Data Cloud mapping. You can only map one stream to profile Data Model Objects (DMOs) for Identity Resolution. This must be a stream of the “Profile” or “Other” type. But that doesn’t mean losing data. Here’s a smart workaround: Send your full order feed as an engagement stream, and create a separate stream for customer data. This lets you fine-tune the customer information specifically for Identity Resolution while preserving complete order details.
Another common challenge? Fake or placeholder data. Customers sometimes enter nonsense information like ‘[email protected]’ or phone numbers of all zeros. These entries can mess up your Identity Resolution rules.
The solution is blacklisting. This means strategically filtering out or nullifying these low-quality data points. But how do you know what to filter?
Data profiling is your friend here. By analyzing your historical data, you can:
- Identify common placeholder values
- Spot unusual patterns
- Create smart rules for filtering out bad data.
Important: Effective data preparation isn’t just about collecting information. It’s about collecting the right information.
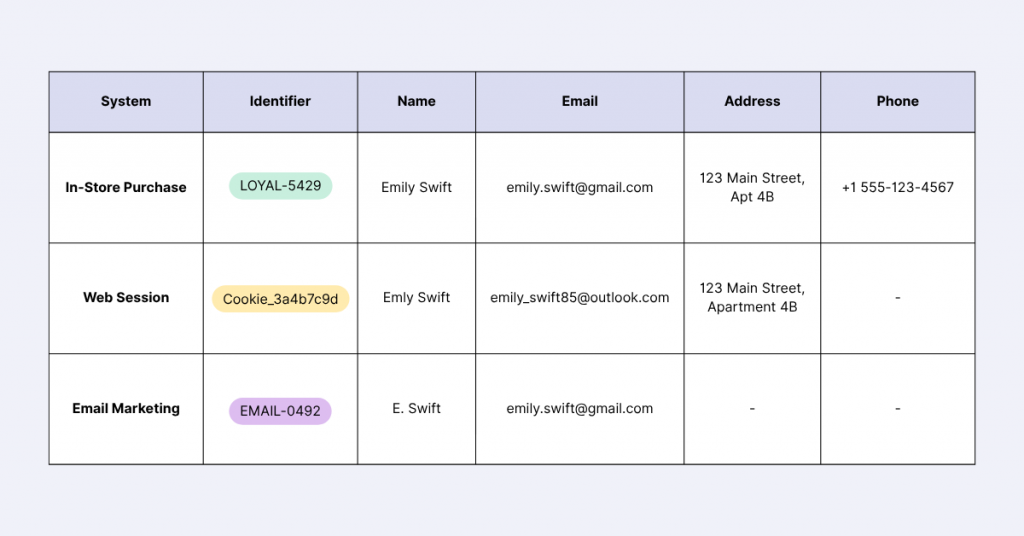
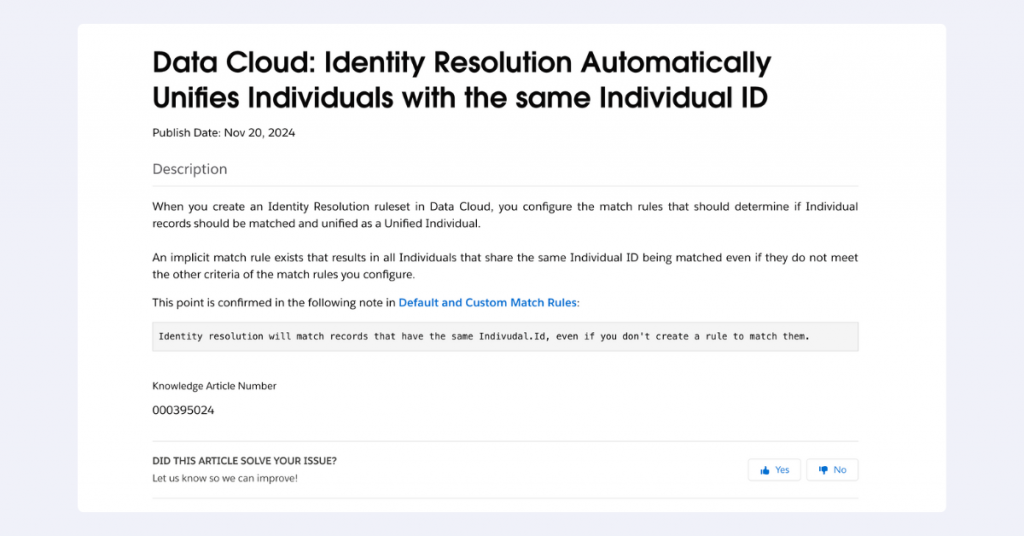
Managing individual IDs: The silent unification rule
There’s a subtle but powerful rule in Salesforce Data Cloud that catches many implementers by surprise. If multiple records share the same Individual ID, they will automatically unite – even without explicit Identity Resolution ruleset configurations.
We learned this the hard way during our own implementation. While setting up our main data streams, our initial quality assurance revealed that records weren’t unifying as we expected. After digging into Salesforce documentation, we uncovered a critical insight about Individual ID behavior.
To add to the topic of Individual IDs, many beginners make a common mistake: assuming the same identifier should work across all marketing channels. But that’s not the case. Each data stream might require a unique approach to identifying individuals:
- Email Marketing: Use email as the primary identifier
- SMS Marketing: Leverage phone numbers
- Web Tracking: Utilize cookie-based customer IDs.
The goal is to choose IDs that most authentically represent your customer in each specific system. This nuanced approach ensures more accurate profile unification and richer customer insights.
Pro tip: Carefully map out your Individual ID strategy before implementing Data Cloud. The right approach can save you hours of troubleshooting later.
The importance of mapping to contact point DMOs
You might be tempted to take a shortcut. “Why map data to multiple DMOs?” you’ll ask. “Can’t I just map everything to the Individual DMO, especially if my data setup isn’t complex?” Here’s the reality: No, you can’t.
When you start creating Identity Resolution rules, you’ll hit unexpected roadblocks. Mapping only to the Individual DMO creates significant limitations. Data Cloud wants stricter rules and won’t allow you to create rules using just the Individual DMO.
Below is an example. Data Cloud asks for more match criteria. The issue is not that you need more than 6 criteria. You’ll notice that once you add other DMOs to the rules, you will overcome a lot of such red error messages.
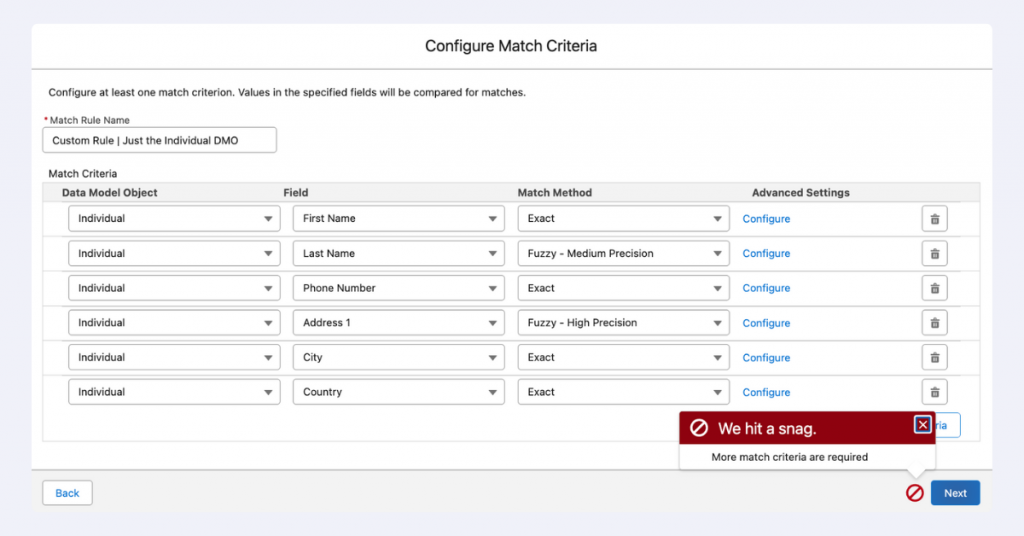
Having data available across different DMOs – Contact Point Address, Contact Point Phone, Contact Point Email, and Party Identification – makes rule creation much more flexible and straightforward. Think of these DMOs like different puzzle pieces that help you build a complete customer profile.
Ensuring data uniqueness through primary keys and deduplication
In Data Cloud, uniqueness matters more than you might think. Individual and Contact Point IDs must be unique within each data source. If you have duplicate primary keys, Data Cloud will discard extra records (it’s expectable overall that primary keys must be unique).
Imagine this scenario: You’re tracking address information, using Address Line 1 as your primary key. But here’s the catch – that single address might actually represent completely different people or locations. Without careful key generation, you’ll lose valuable data.
To prevent losing important information, get creative with your key generation. For addresses, consider creating a more specific identifier by combining multiple data points. A smart approach might be concatenating:
- Full Name
- Full Address.
Below is a visual showing what’s happening to the mapping of data from the same data source to the Contact Point Address primary key.
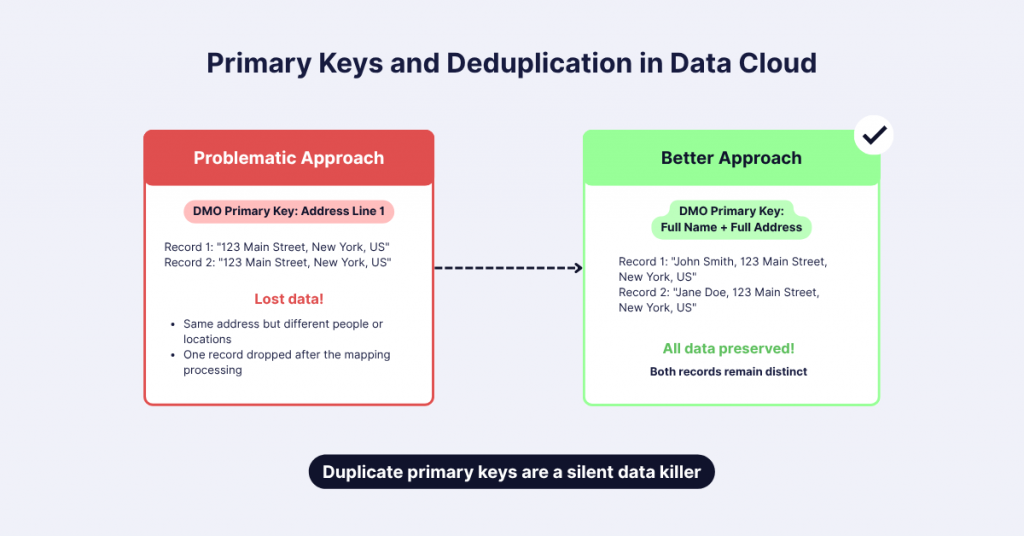
Important: Duplicate primary keys are a silent data killer.
By creating a more granular primary key, you ensure that each record remains distinct and no critical information gets discarded during the data ingestion process.
Always think beyond the obvious when creating unique identifiers. The more specific your key, the more data you preserve.
Understanding web tracking with behavior and profile streams
When implementing Web SDK tracking in Data Cloud, there’s a subtle but important distinction in how customer interactions are captured.
All web interactions are collected in the behavior stream, but only identified users make it into the individual Web profile stream. This might sound confusing at first, but there’s solid logic behind this approach.
During our implementation, we did a thorough quality assurance check comparing identified customers across streams. What we found confirmed the system’s design: every record in the profile Web stream was present in the broader web stream.
Important: Anonymous users (those with only a cookie ID) aren’t automatically added to the profile stream.
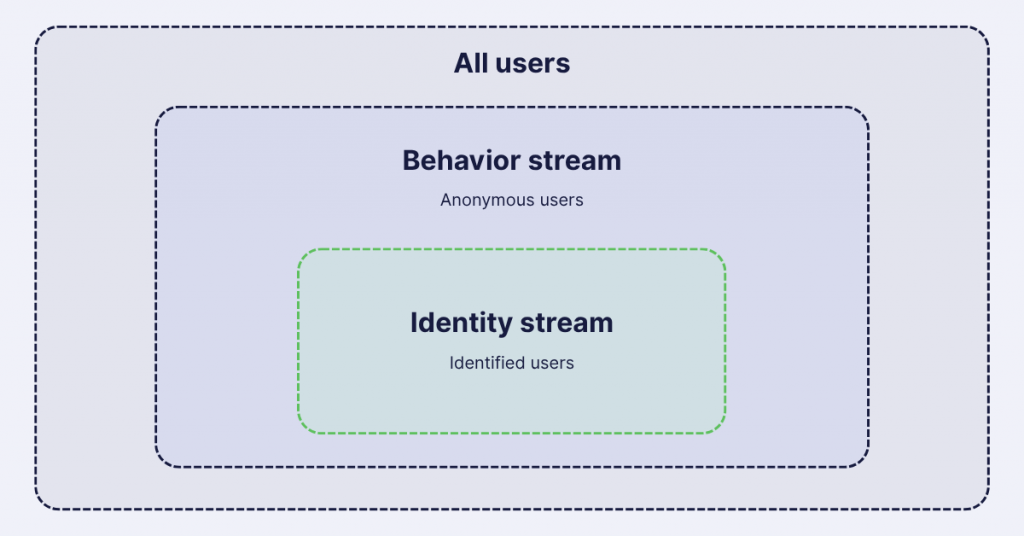
This makes practical sense. It’s challenging to meaningfully connect with customers when you only have an anonymous tracking ID. As users become identified over time – by logging in, making a purchase, or providing contact details – they’ll start appearing in the profile stream.
There’s an added business benefit, too. Many companies are billed based on the number of unified customer profiles. This approach helps prevent unnecessary billing for unidentified, anonymous web visitors.
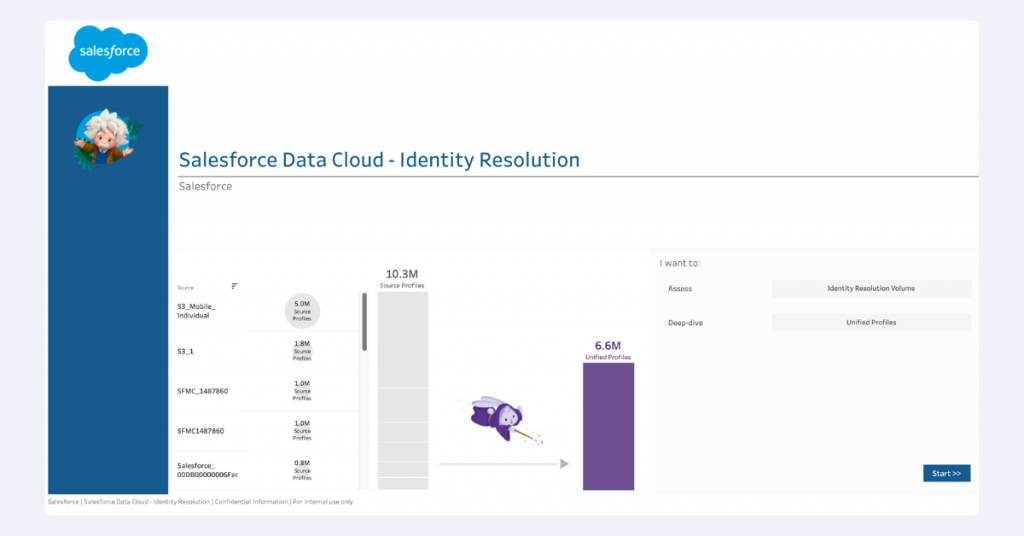
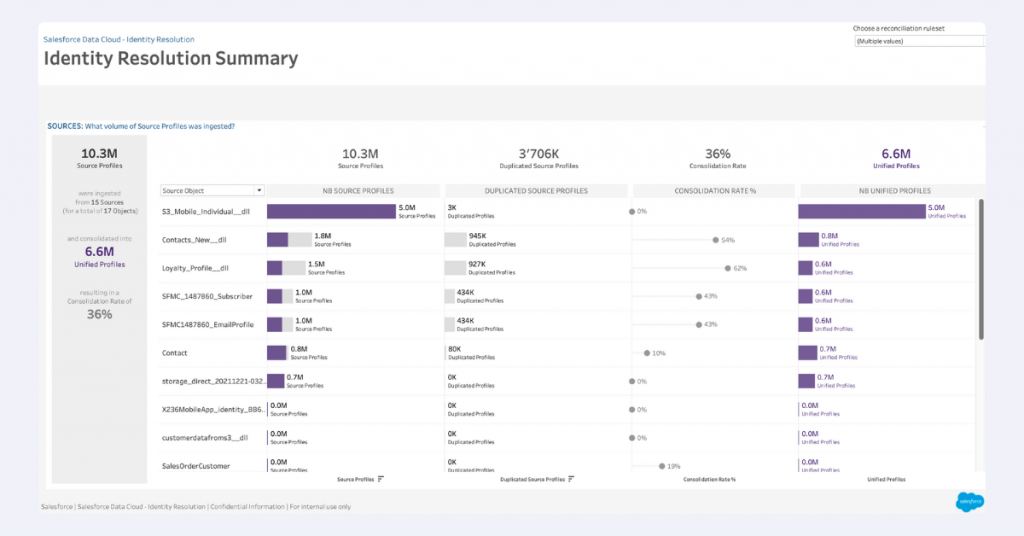
Quality assurance tools: Query Editor and Tableau
It’s important to QA your data setup, identity resolution included. One of the built-in tools I like using is Query Editor, where with the help of SQL you can explore your DLOs and DMOs.
While powerful, this approach has limitations: it may present a steep learning curve for team members less familiar with SQL and lacks strong visualization capabilities.
An effective alternative is to connect Data Cloud to a dedicated BI tool. Though SFDC includes native BI capabilities, we’ve found external tools often provide greater flexibility. Tableau stands out as a particularly good match, as both Tableau and Data Cloud are part of the Salesforce ecosystem, ensuring good integration.
With Tableau, you can connect directly to your Data Cloud objects, create visualizations that reveal identity resolution insights, and build detailed tables showing unified individual IDs alongside their raw input attributes. This visual approach makes it much easier to spot areas of concern and quickly diagnose problematic profile aggregations, helping you understand what’s causing issues with certain profiles.
You can make a custom dashboard addressing your needs, or you can use an accelerator from Salesforce. ‘Accelerators’ is the term used by them for dashboard templates.
Salesforce has an accelerator tailored specifically for Identity Resolution. You can access it here.
Conclusion
Effective identity resolution is the cornerstone of truly understanding your customers. With Salesforce Data Cloud, your business can turn fragmented data into unified, actionable insights, enabling more meaningful connections and smarter decisions.
Remember, every implementation has its unique challenges and opportunities. By carefully preparing your data, strategically managing identifiers, and continuously adapting your approach, you’ll set the foundation for more accurate insights and better business decisions.
Need support implementing or enhancing identity resolution in Salesforce Data Cloud? Our certified specialists are here to help. Get in touch today and let’s make your Data Cloud project a success.

Share on: