
Given the significant role of SEO in every eCommerce manager’s life, we’re releasing an SEO Crash Course that covers and explains all the main aspects of SEO, from robots.txt to 301 mapping, and everything in-between.
What’s in store? Exclusive insights from supporting more than 40 Magento migration projects from an SEO perspective summarized in 8 videos.
First up – Magento robots.txt
In the first published lesson, learn what robots.txt files are, how to guide crawler behavior, and how crawler restricting can improve website performance.
Topics covered in this video:
- Robots.txt file: what it is and what it does
- Meta robots
- ‘no index’, ‘no follow’
- applying meta robots in HTML for PWA
- X-Robots-Tag: what issues you can solve by implementing it.
Robots.txt file – what is it?
Robots.txt is a file that limits search engines from crawling certain pages. This file is located in the root folder on the website (e.g., example.com/robots.txt).
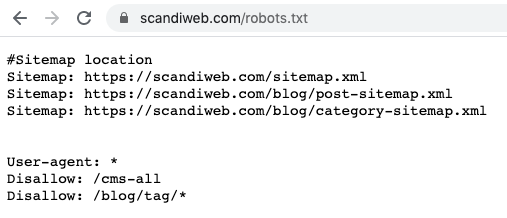
If you are running an eCommerce store, especially on the Magento platform, we strongly recommended having a robots.txt file. Allowing search engine crawlers to crawl too many pages can harm your server performance. Robots.txt can help to ensure that:
- Sensitive content, e.g., login information and user accounts, is not crawled
- Search engines can easily find your website’s XML sitemap location.
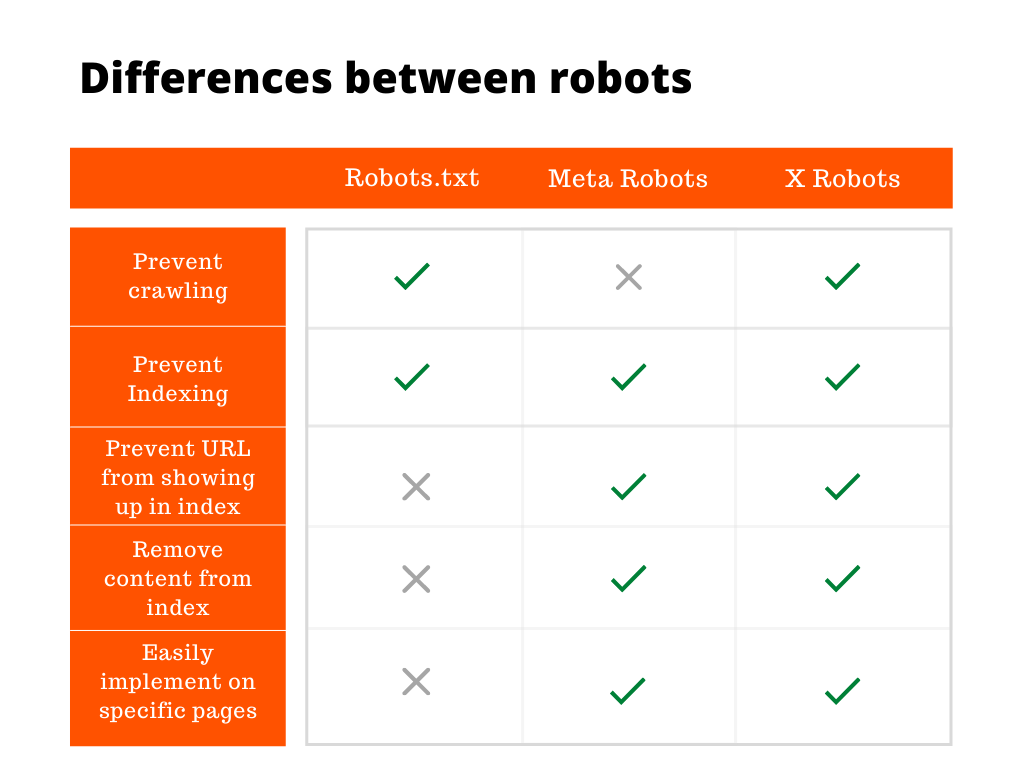
There is more than one robot used to prevent crawling or indexing certain URLs or the whole website. The most widely used element is meta robots.
How do meta robots help to control your website content?
When a customer is looking for a product on your eCommerce store, he is usually able to filter search results by brand name, price, colors, etc. Each filter, navigation, and combination of all values have unique URLs. There could be hundreds, thousands, and even millions of such URLs on your website. To avoid URLs conflicting with each other and help to control the website content displayed in search results, you can use meta robots/meta tags.

The ‘no index’ and ‘no follow’ is the most commonly used tag that instructs the search engine. Google can still crawl your website but isn’t allowed to display certain pages in search results.
Meta robots in PWA
Google and other search engines might have issues rendering JavaScript. There are several workarounds you can apply to exclude pages from the index for PWA websites. Implementing X-Robots-Tag as a server response (HTTP) header will help you to ensure Google sees the tag right away.
Listen to all the details regarding the rather broad robots.txt topic in the video lesson above. In lesson 2, Lina, the voice behind Scandiweb’s SEO Crash Course, covers canonical tags and how to deal with duplicate content.
Need assistance in improving your position in search results? Have additional SEO concerns? Let us help you! Feel free to browse our SEO services and don’t hesitate to get in touch!

Share on: