
Many marketers and site owners have been living in fear of duplicate content ever since Google released the Panda update in 2011. Let’s dive into the topic of duplicate content and what site owners need to consider when it comes to duplicate content, what is and what is not considered an issue, and how to fix duplicate content.
What is duplicate content and why does it matter in SEO?
Google defines duplicate content as “substantive blocks of content within or across domains that either completely match other content in the same language or are appreciably similar.” So in other words, if the same or similar content appears somewhere on the internet on two or more pages at the same time, that could be considered as duplicate content.
And just like a user would, search engines could also get quite confused as to which version of the content is the main one and the correct one to show when someone does a search. Because of this, duplicate content can impact search engine rankings.
How does duplicate content affect SEO?
The greatest fear of marketers is that duplicate content clearly spells penalty. But let’s get something straight: Penalties are rare. It’s really more of a myth than truth. Google will not penalize your site just because of that small snippet on your blog that you took from another source. So don’t let this fear cripple you as a marketer or site owner.
That said, duplicate content is still something that site owners need to pay attention to. And we get it if you’re still asking, “What is duplicate content?” at this point. Understanding the two big types of duplicate content and when duplicate content may cause you trouble and negatively affect SEO will help you decide on what to do.

External duplicate content
External or offsite duplication is when exactly the same or very similar content is found in two or more different domains.
Sounds pretty straightforward, right?
Copying other people’s work and adding it to your website without attribution is obviously not okay—that’s a breach of copyright. And if you do that, that’s counted as content duplication.
But sometimes, simply copying over existing content to your website just makes sense, which a lot of site owners do in certain situations. For example, using the product description the manufacturer has sent you on the product page on your website is quite common practice.
Unintentional duplicate content can also occur, like unknowingly having the exact same sentence on your page that can be found on some other content piece on another website.
So all these scenarios point to you having duplicate content. Does it mean you are in trouble if they are true in your case? Well, if you are guilty of copyright infringement, then you could be. But in the other two examples, you don’t really have to worry. Intentionally and maliciously using duplicate content is what will get you in trouble.
Duplicate content scenarios
Situation 1: Website X published a blog post about Duplicate Content and SEO. In their intro paragraph, they wanted to add the official Google definition of duplicate content, so they copied those few sentences and added them to their blog as a quote and linked to the original source. The quote is surrounded by their own content.
Situation 2: Website Y has published a great guide that you found really useful so you decided to post it on your website—without asking them for permission and without adding a cross-domain canonical tag.
Situation 3: Your competitor website has posted a curated roundup article listing their followers’ Tweets about a social issue.
Which of these situations is duplicate content by Google’s definition?
Which of these scenarios are bad for SEO?
In Situation 1, everything is perfectly fine. Only a small quote was added and the original source was linked to. By Google’s definition, duplicate content involves “substantive blocks of content.”
In Situation 2, however, we see a perfect example of what not to do. Google will definitely see what you’ve done.
Situation 3 explains a curated roundup—in this case, an article that compiles a list of Twitter posts about a topic relevant to the readers. Websites that publish this type of article usually review the opinions cited and provide their own unique insights.
All the above situations seem to illustrate the occurrence of duplicate content. But hear this—not in the eyes of Google. Only Situation 2 would make Google blink an eye.
Internal duplicate content
While external duplicate content and related issues are what most business owners are concerned about, internal duplicate content often goes unnoticed. If the same is true in your case, this lack of attention to internal duplicate content could be detrimental to your ranking and lead to you losing the ability to control which pages get indexed and not.
When Googlebot crawls your page and finds the same or similar content on several pages, it can get confused as to which of the similar pages you want to show up in SERPs, given specific keywords. Besides, its valuable crawl budget also gets wasted crawling many pages instead of perhaps just one. It’s a waste of resources.
Duplicate metadata, large pieces of boilerplate content on multiple pages, and several pages speaking about the same topic can all contribute to the problem and increase the chances of Google indexing the wrong content, basically choosing on its own the canonical version of the pages—which might not be what you consider to be your main page and would like to get indexed.
Keyword cannibalization
If several pages with similar content in them end up in the Google index, they will most likely target and rank for the same keywords, or keywords they are ranking for will overlap in some part. This is bad for SEO.
Why keyword cannibalization is bad for SEO
If instead of having all your great content about a specific topic consolidated in a single page, you have it distributed among several pages, the resulting pages will be competing with each other for the same keywords. When this happens, it decreases your chances of actually ranking higher for the affected keywords, ultimately hurting your website’s organic performance.
In other words, you could get more organic traffic if you combined those separate pages into one. But pay attention to the next question.
Should you always combine similar pages into one?
Combining certain pages might bring you more traffic, or it might not. It really depends on the situation. So it may not always be the best solution or the right thing to do. A number of pages ranking for the same keyword or several different keywords may be fine, depending on various factors.
For instance, if a page is ranking well for a few keywords, it will most likely rank for tens or hundreds of other keywords as well. If one of those other keywords also happens to be ranking for some other page on your site, it is not likely to have any impact on your overall organic performance. That is because the pages concerned are most probably ranking for many unique keywords of their own.
If you were to delete one of these pages or merge them together, you would likely be losing more than gaining something.
Therefore, what you should be concerned about are pages that not only rank for the same keywords but also fulfill the same or similar intent with their content.
Sources of duplicate content in eCommerce
Issues surrounding thin, low-quality content and lots of similar pages trying to rank for the same keywords can easily turn into a disaster when it comes to eCommerce SEO. And large eCommerce stores with thousands of product variations and/or filters available on category pages are especially prone to this.
Let’s look at the different aspects that you need to consider if you want to avoid such an SEO catastrophe.
URL variations
Thousands and thousands of Session IDs and URL parameters that end up in Google’s index by improper SEO setup can all contribute to duplicate content.
Layered navigation filters and layered navigation
A type of URL variation most eCommerce stores are very likely familiar with are layered navigation filters and their combinations (e.g., ?price=10; ?dir=desc).

Depending on the setup, applying filters and/or sorting options on product category pages may create specific URLs with filter/sorting parameters added to the URL. And depending on how many different filters there are available, combinations of filters can create thousands of different URLs. From an SEO perspective, this can be very dangerous. If not handled correctly, these URLs can get out of hand and flood Google’s index with tons of duplicate pages.
Product variants
Configurable products that have two or more variants available may create a number of almost identical pages served through different URLs. If there is no search volume for keywords the product variant pages could be optimized to target, it is a good idea to de-index these product variants and index only clear products without variant parameters added.
Internal Search result pages
Most e-commerce stores will have an option to search within it.

Search Results pages are another type of page that can contribute to duplicate content if indexed, as they have no unique content.
Trailing slashes on URLs
Inconsistent URL structure within internal linking is quite a common improvement area for many eCommerce stores. Search engines like Google consider URLs with and without the trailing slash at the end to be completely different and unique URLs. Hence, if you are providing both /example/ and /example to search engines, both might get indexed, even though they are just copies.
Duplicate category or product pages
Big eCommerce stores with many categories and subcategories can often experience duplication across categories/subcategories.
For example, for a variety of generally well-intended reasons, a subcategory “Watermelon” could get added under two parent categories, say, “Fruit” and “Berries.” This would mean that the subcategory would be available through two URLs: /fruit/watermelon and /berries/watermelon. And as you could easily imagine, these URLs will list the same products and have the same product descriptions.
Similarly with product pages, if a product gets added to two or more different categories, it will appear under all of them and create different URLs, e.g., /fruit/watermelon/seedless-watermelon and /berries/watermelon/seedless-watermelon.
These occurrences confuse Google and prevent it from clearly understanding your site’s structure. Google then finds it difficult to tell which pages are really important and it should be looking at. And we’ve already mentioned that leaving Google confused like this is not something that you want to do.
Fortunately, most big eCommerce platforms like Magento (Magento Commerce) and Shopify will generally prevent this from happening as the product canonical tags will always point to short product URLs, i.e., without the category path (e.g. /seedless-watermelon).
Boilerplate content
Boilerplate content is generally harmless, yet it can become rather troublesome when it comes to eCommerce websites.
Simply put, boilerplate content is any piece of content with no great importance. It is usually repeated across multiple, even all, pages of a website without being changed. For example, all the text of the header and footer of your website is boilerplate content, just as the text on your navigation menu is.
Almost all pages on the internet will have some boilerplate content in them. And that is generally fine.
Now you’re probably wondering—why and when can boilerplate content be an issue, then?
Consider this scenario: If your Delivery Policy or FAQ appears on every single product page and it is quite a long sheet of text, then you are confusing Google again. Say, a page is about “Beige Hiking Boots from Real Leather” but 90% of the text on the page is about your terms of delivery—how do you think Google will read it? For obvious reasons, you can’t expect Google to rank your page high in SERPs for that product keyword—which means that Google is probably going for your competitor’s page if they’ve got more relevant content.
To avoid this mistake, and as a general practice, you should shorten chunks of text that are boilerplate content or simply add a link to the relevant pages.
Product descriptions
It is common practice for eCommerce websites to reuse product descriptions exactly as provided by manufacturers. But this being common doesn’t mean that it is good practice.
Because many websites do this, product descriptions with the exact same text can be found across many different websites selling the same products. If you’re selling the same products, you’d want to rank higher on the SERPs so you can get better chances of getting the attention of interested shoppers. But sharing the same product descriptions with possibly hundreds of other eCommerce stores makes that objective extremely difficult to achieve, unless perhaps you have a highly authoritative website with loads of backlinks.
What we recommend is that you go one step further by performing keyword research and writing unique product descriptions for your eCommerce website. It will not only help you rank better in SERPs and get more traffic, but it will also better engage the users that land on your product pages. After all, you want those visitors to convert and actually complete a purchase.
How to avoid duplicate content issues?
To avoid duplicate content issues, it is always a good idea to have an SEO team involved at the start of a project or whenever new content is added to your website. When duplicate content has accumulated over the years, it could be very difficult to identify and eventually eliminate all of them.
Focus on creating unique content
We did mention that adding information from other websites is fine so long as the source is properly attributed. A short quote will do no harm and can even add a lot of value if it is from a highly authoritative source. Nevertheless, we cannot emphasize enough the importance of creating high quality, unique content.
Don’t go the seemingly easy route and copy-paste product descriptions provided to you by manufacturers on your product pages. Invest in your product descriptions and have your team craft unique content for your eCommerce store.
Maintain consistency with internal linking
We’ve already mentioned how inconsistent URL structure can contribute to duplicate content. To avoid making the same page available through different URLs—an error easily committed by adding a trailing slash at the end of a URL where there should be none—ensure that a consistent approach is maintained whenever content is created or modified.
For instance, if the canonical version of a landing page is /example (without a trailing slash), then make sure that only this version of the page gets linked to all across the website and not /example/ or any other version.
Perform keyword research
Before adding new content or pages to your website, it is always a good idea to check that pages with the same or very similar content and intent do not exist yet.
Make sure the robots.txt is blocking appropriate content
We’ve already mentioned that we don’t want duplicate content getting indexed as it is bad for SEO. Now we want to add that some of these pages should not even be crawled at all.
There is an infinite number of URLs that can be generated from internal searches. Although in most cases this simply means that web crawlers will be wasting their crawl budget on these pages, on the flip side it also means that attention is on those useless pages instead of on your more valuable content. Hence, blocking URLs from an internal search from being crawled by search engines makes sense. You can do this by adding a rule in your robots.txt that would disallow the crawling of such URLs.
How to find duplicate content on a website?
Avoiding duplicate content in the first place is the best thing to do. But if you’d like to check whether there is already duplicate content on your website and how much, there are duplicate content tools or checkers that you can use.
Here are some of the tools that we recommend:
- Siteliner – can be used to regularly check your entire website for duplicate content and broken links
- Plagspotter – a duplicate content checker and monitoring tool that scans a web page for similar content on the web, providing links to copies found online
- Copyscape – a comparison tool that highlights duplicate content; also indicates how much of the content matches existing content elsewhere on the web
- Duplichecker – a plagiarism checker that searches for duplicate content published on the web
How to solve duplicate content issues?
What is the most common fix for duplicate content? As duplicate content can come in many different forms, there is no one way to fix it. The solution would depend on the type of duplicate content you are trying to address. But here’s how to fix duplicate content given common scenarios.
301 redirects
For many cases, a 301 redirect is the best option. Simply apply a 301 redirect from the duplicate page to the original (main) one.
As simple as it may sound, deciding on which pages to keep or redirect could be tricky. But here are good indicators of whether a page should stay or go: traffic and backlinks. Which page is receiving the most traffic? Which one has many backlinks pointing to it? These questions will help you figure out the answer.
What if your other pages also have some backlinks? How to fix duplicate content in this case? No need to worry. The so-called link juice is passed on with a 301 redirect. Any backlink “votes” a redirected page has accumulated over time will be passed to the designated “correct” page—which contributes to increasing its potential to rank higher.
A 301 redirect is usually the solution for duplicate content caused by trailing slashes being added to URLs.
Canonical tags
Another option that can help deal with duplicate content are canonical tags.
Canonical tags are used to indicate which copy of the page is the superior one and tell search engines to index that page. All the link power of the copies would be attributed to the canonical version of the page.
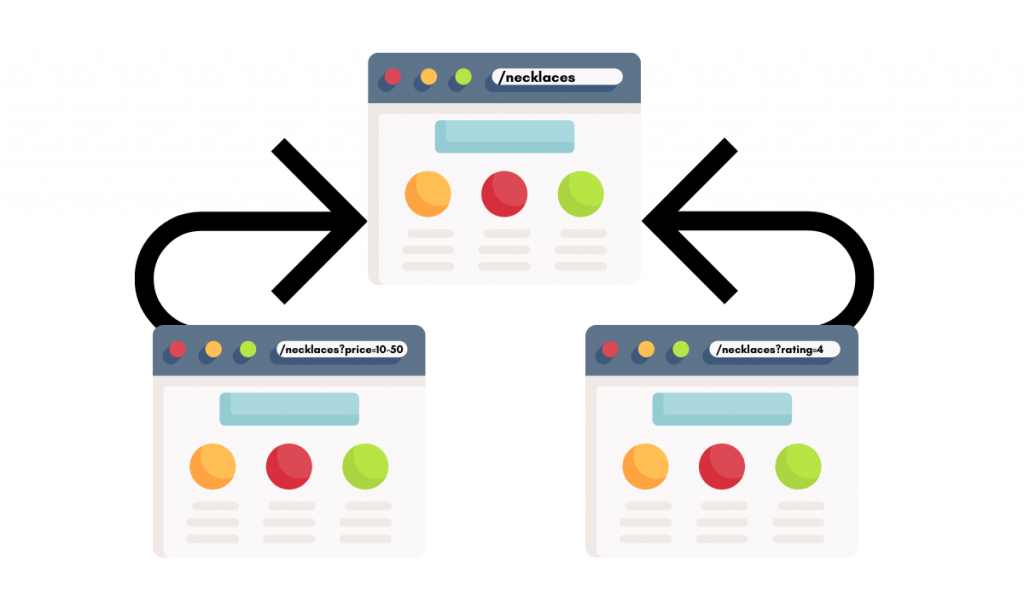
Here’s how to fix duplicate content with canonical tags: In eCommerce SEO, we would typically canonicalize the layered-navigation-generated URLs and other parameters to the clean category page. So, /necklaces?price=10-50 would have a canonical tag pointing to /necklaces.
Meta robots “noindex”
Although generally not recommended, another option for fixing duplicate content issues is simply adding the robots meta tag “noindex, nofollow” or “noindex, follow” to the page you don’t want to get indexed, i.e., the duplicate version. This is mostly used in cases where a page still needs to be present, serving some purpose for the users, that it cannot be deleted or 301-redirected.
Google has recommended against using “noindex” and a canonical tag on the same page, as that can give Google conflicting signals. From one side, you’re saying “don’t index THIS page,” but from the other, you’re giving Google a signal that this page is a copy of THAT other page. This could make Google believe that the other page is also to be noindex-ed.
So there. Now you should know how to fix duplicate content given these common scenarios.
Settling the debate
How much duplicate content is acceptable?
As previously mentioned, Google will more than likely NOT penalize you for duplicate content. And there is no specific number of duplicate content you are allowed to have, regardless of what anyone is saying. Don’t think in that direction. Rather, think of how that duplicate content might impact the main content’s ability to rank, as described in the previous sections of this article.
In the case of a multi-language store, is a translated version of the page considered duplicate content?
No. Nope. Definitely not.
So if you have one page in English, for example, and have the same content translated into French on another page, it will not be considered duplicate content. Those are literally different words you are using there.
And even if you have a store with multiple store views and each of those store views has different English versions, like Canadian English in one and Australian English in another, they should not be considered duplicate content. The hreflang tags play an important role here because they properly inform the search engines that those are alternative pages intended for different sets of audiences. So make sure you are using hreflang tags.
Should you stop worrying about duplicate content?
We’ve said it more than once—duplicate content issues can be tricky to find and fix if they’ve been left unattended for a long time. So, the answer can be best summarized this way: You should keep an eye on duplicate content but you shouldn’t worry too much about it that you become limited in what you are willing to do with your content. Our practical advice would be to regularly run site checks and be more mindful when adding new content to your website.
And that’s it! Debate settled.
We hope you start focusing on creating unique and engaging content for your users instead of unnecessarily stressing about duplicate content. It’s good for you, good for your users, and definitely good for SEO.
Worried your site might be suffering from duplicate content issues? Or just want to make sure it is not? Write to us at [email protected] or just hit the orange chat bubble you see on the bottom right corner.

Share on: